This post is based on the interview between Eric Enge and Peter Linsley, Google’s Product Manager for Image Search. It reveals some interesting aspects of image search which is growing at an accelerated pace.
A recent survey by Hitwise in February 2009 shows Google Image Search as part of the troika of top web properties owned by Google in terms of traffic and revenue.
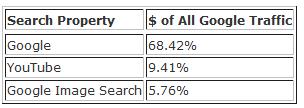 [1]
[1]
Peter’s responses to Eric’s questions are summarised as follows:
1) On Page Factors in Optimising Images:
In web search, the bots crawl structured data, have enough signals like title, headings and sub-headings, the body content, the backlinks and anchor text from external sources etc to size up the intent of the page.
An image search does not have such signals to rely upon. The bot can access the image source tag in the html and the alt text describing what the image both of which are the key determinants. The more clarity the alt tag content has, the better the intent conveyed to the crawlers.
Peter affirms that it is a very good practice to have a clear description of what the image is about in the alt text. For users who are vision impaired or who have images turned off, the alt text clearly conveys the message when the mouse is hovered over the image. It is a bonus if the same alt text is found elsewhere on the page content in the form of the title of the image or part of a caption.
From the crawler’s point of view, it can see the image tag and the alt text but these do not say much about the image itself. Naming parts of the image as in Flickr photos also does not help the crawlers as it is not machine readable.
If the title, description and caption of the image is obvious to the user, Peter says this is a huge help in helping his team figure out the text associated with that image and rank it appropriately.
File name is an important attribute that is analysed as it tags on to the image even if it is embedded many times on a page or if it is linked to by other sites. A meaningful file name helps though it is not a very strong signal in the ranking process.
A few issues related to file names are:
- A lot of operating systems and web servers do not allow file names in other languages that cannot be represented in ASCII. People cannot use certain types of text when naming the file for the same reason.
- Another problem from the human perspecitve is that users cannot do justice when naming the file in their respective language. So the search engines cannot assume that the filename is the best description of the image.
2) The Alt Text:
Peter says that if the image cannot be seen but one can perceive what it looks like, then the alt text should reflect that perception in words. The alt text becomes a replacement for the unseen image.
There is no hard and fast rule on the length of the alt text. It all boils down to how the user would feel about it. The alt text can be as detailed as describing all the details of the image. Peter mentions that having a title, caption and description for the image somewhere on the web page enables the crawlers to treat the image title with the same importance as the equivalent of the HTML page title for that page.
Eric poses a question about the association of caption text with the image by the crawler with an example of Charlie Chaplin dancing in the moonlight with the page content including title tag focused on the same topic. Peter confirms by saying that the association is important to the extent to which the image itself is very important to the page.
The close contextual matching of content to this image is a very strong signal. If the image was removed from that focused page, then it would lose a lot of its value in ranking terms. The key here is to think of it from the user’s perspective. If a user lands on the page on Chaplin and sees a large image of Charlie above the fold, the user can see the relevance straightaway.
If the page has six different sub topics and matching images for each sub topic as in the case of a blog about San Francisco with different posts about the place, Peter says the crawlers are pretty good at figuring out the different topics and the images relevant to each sub topic.
Having a permalink for each of the sub-topics is a big help. A canonical tag on each of the inner pages that contains the detailed post and relevant images also helps the crawlers know the canonical url for the image.
3) Matching An Image And Its Content:
There are a number of ways in which a crawler tries to figure out what an image is about, the content and how it matches the intent of a user search. Machines find it a problem to read what an image is and decipher what it represents.
Peter cites an example of an image showing a shark jumping over the Golden Gate bridge. To humans, the scenario is very obvious. The caption of the image says – Check this out. This does not make any sense to a crawler in figuring out what the image is about unless the pixels of the image are analysed. All the other factors discussed above do add to the confidence level of the image aiding the image search team in trying to figure out the image correctly.
4) Signals In Two Dimensional HTML World Vs Three Dimensional Image World:
Eric mentions the two dimensions of relevance and importance (in the form of backlinks) in the HTML world that are important signals on the page. But in image search, apart from the relevance and importance, the third factor of confidence comes into play.
Peter agrees wholeheartedly and says that unlike external links to a page that are counted as votes in web search, images are seldom linked that way. The search team has to consider the other signals to see if they are talking about the image and appropriately factor them into the algorithm.
5) Web Page Influencing the Ranking of Images:
Peter admits that a web page is certainly a signal in the ranking of images. In a nutshell, from the SEO perspective for image search, all the rules that apply to web serach apply equally in image search also. Being an authority on a certain topic and embellishing the page with unique content all provide signals that help the image as well.
So a page with great content and links from other sites to it and other positivbe external signals associated with it inherently passes on the benefits to images that reside on the page.
For images being above the fold or scattered on a page, Peter says that the user experience is a very important factor. If images add to the relevancy and usefulness of the user experience, then it is a vital factor in conjunction with other signals to return this page in the results. This relevance also proves to users that the results for an image search are very relevant to the user’s query and approved by Google to direct the user to the site.
The image search team try to return the best possible images for queries. It must be remembered that there are lots of sites with competing images that are relevant to the user queries.
6) Difference in Results Between Universal Search and Image Search:
Peter and his team realise that there is a subtle difference in intent of a search query made on web search and specifically on images.google.com for an image search. Users doing a specific image search are definitely looking for image results. It is not the case with universal search though relevant results from different verticals are presented on the SERPs. The intent may differ based on the web property the users perform a search.
7) Combating Spam in Image Search:
The image search inherits all the benefits of the work done by the Google web spam team. All the good practices that apply to web search pretty much apply to image search also.
8.Growth of Image Search and Related Technology:
Peter agrees that image search is a really hot and developing web property with incredible scope for the future. It could end up amassing trillions of images in time to come. It is a huge task indexing and organizing the unique images in the explosively growing image world. Each person’s view of the world is unique and it is reflected in the creation of images.
Peter asks a most interesting question – If someone is interested in seeing only an image, why should the search start with a text query? The solution to this has arrived in the form of the Similar Images [2] launch, a Google Labs project where users can search for images based on existing images. The search is completely visual.
A query like Paris can return results on Paris Hilton, Paris in France, Paris in Texas and the Eiffel Tower in a good search engine. With Similar Images, you can start off with an image and take it as an additional query in your exploration along with the original text query. The image at that point is used as the next query.
With the fall in prices for good quality digital cameras and increasing quality of mobile phone cameras, taking pictures has never been easier and so very affordable. The technological advances in facial recognition software (an aspect of it is used in Google’s Picassa tool) is also helping the image search team in their quest to organize the image world to give it more purpose and a huge reach in the future.
The entire transcript of the interview on Google Image Search [3] that forms the basis of this post makes an interesting read.
Ravi Venkatesan is a senior SEO consultant at Netconcepts [4], an Auckland search engine optimisation [5] company that offers great SEO services to its clients based in New Zealand and Australia.