Blindfolded SEO Audit Part 1
SEO consultants spend a lot of time looking at websites. Moreover, like web designers, SEOs definitely “see” websites very differently than the average web user. Some days, it feels a little like the Matrix, where instead of seeing the streaming code, you see the people, cars and buildings that the code signifies. After doing web design, this is heightened even more, although perhaps inverted … instead of seeing shoes, cookware, and dog collars, I see title tags, heading tags, URL constructs and CSS.
Like any skill though, it takes continual honing and refining, along with the education. This is part of the concept behind the 60-Second Website Audit and training the eye to quickly identify key SEO issues and potential issues.
I’ve joked that, after so many audits, SEO consultants could probably do them blindfolded. So, whip out the blindfold and let’s put that to a test.
Okay, so maybe not really blindfolded, but how about auditing a site without actually seeing the site? Hmm, that might be interesting. This is more than gimmick. In fact, though I might normally take a quick look around a site, ala 60-Second Audit, I generally start the deep dive of an audit exactly as I’m going to show you.
So how do I start auditing a site without looking at the actual site? Just like a search engine, I start at the crawl, which is what we are going to do today. SEO is about so much more than just keywords, and while the title tag is one of the most important signals a site can send to a search engine, a title tag that can’t be found is of little value.
Let’s Audit, Blindfolded
I needed a website I haven’t seen before for this experiment. To pick a site randomly that I haven’t seen, I started by picking a word and searching in Google for it. Being mid-October and feeling the quick approach of winter, the word “sweater” seemed aptly appropriate. I then jumped to the 5th page of results and selected the 2nd result, which was ColdWaterCreek.com. While I know of Cold Water Creek, I don’t recall ever seeing their site, so this is perfect.
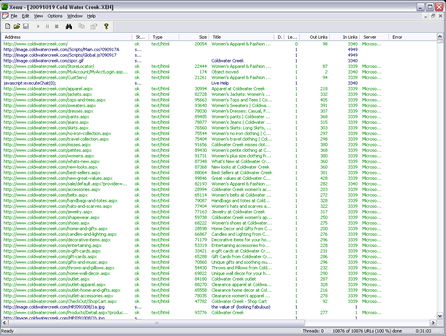
Let me introduce you to Xenu. Xenu Link Sleuth™ is a free crawler program that you can download and use to crawl your own site (highly recommend) or other sites. Xenu is one of the most powerful (and perhaps underrated) tools an SEO can have. The amount of information from this tool is priceless, and in this case, will be how we’ll start to audit ColdWaterCreek.com “blindfolded.” That said, if you want to try this at home, I’d recommend doing so on your own site, rather than everyone running out and crawling Cold Water Creek’s site!
Since I prefer to work with the data within Excel, the first thing I do after running it is to export it out to a tab separated format that can be imported into Excel. The details of using Xenu are beyond the scope of this post, so if you are new to Xenu, I highly recommend spending a little time reading first.
After moving the external URLs/links, which in this case also includes the images to another tab, I’m left with 5,161 rows of data, or in other words, 5,161 URLs. When I do a site:www.coldwatercreek.com search in Google (appending &filter=0&start=990 to the URL), I see Google returns 820 results. Quite a difference … what’s the true number?
No idea, but most clients feel that the Google number is often far less than the number of URLs (pages) they have and Xenu seems like a lot more than they expect. I certainly don’t expect Google (or any other search engine) to index 100% of a site’s URLs, but seeing less than 16% indexed based on the Xenu number tells me there may be some issues. Remember though, I haven’t even looked at the site so I don’t really have any idea what those issues are yet.
More importantly, and I see this time after time, we don’t know whether the “true” number should be closer to the Google number or the Xenu number. Too often, people view indexation numbers as something that needs to be increased, that more is better. But more could just as well be indicative of problems.
Next, I note that the server is running Windows IIS as the server platform. I see this in part by the .aspx file extension, but confirmed by the “Server” column of the Xenu report, which lists the URLs as Microsoft-IIS/6.0. In a normal audit, this would clue me in on two things, the first being that I want to be aware of possible case issues. Since IIS doesn’t distinguish case differences, this means that we might see somewhat “sloppy” or inconsistent linking references, such as default.aspx vs. Default.aspx, or blue-jeans.aspx, Blue-Jeans.aspx, Blue-jeans.aspx or even blue-Jeans.aspx. While the server may gladly serve up the appropriate content for these variations, search engine spiders recognize that these could be different pages on other serves, such as Linux, which means that each of these URLs are unique.
Second, this also alerts us to proper redirection challenges. Setting up 301 permanent redirects vs. 302 redirects in IIS seems to trip up many IT departments. So now, we know that this may be a roadblock to any recommendations we make, or that we really need to double check that they have been done in the past and that they are done correctly going forward.
A quick scan is all that is needed to find examples of the case issue:
- http://www.coldwatercreek.com/StoreLocator/Store_Details.aspx?StoreID=9126
- http://www.coldwatercreek.com/Storelocator/Store_Details.aspx?StoreID=9126
- http://www.coldwatercreek.com/StoreLocator/Store_Events.aspx?StoreID=146
- http://www.coldwatercreek.com/Storelocator/Store_Events.aspx?StoreID=146
See the differences above? One version uses an upper case “L” while the other version uses a lower case “l” within StoreLocator. This means that there are likely duplicates of all of the stores for the details and events pages. Fortunately, the rest of the URLs are pretty clean and consistent, which isn’t always the case (no pun intended).
After sorting by URL, we quickly see some other common issues. Ironically, this issue is less about the content that is there and more about what isn’t there. Toward the top of the list, we find these URLs:
- http://www.coldwatercreek.com/%2f404.htm
- http://www.coldwatercreek.com/404.htm
- http://www.coldwatercreek.com/404.htm?aspxerrorpath=/MyAccount/MyAccount/MyAcctLogin.aspx
First, the %2f is the encoding for the “/” which tells me that there is probably a malformed URL here. The real issue though is that all of these represent a 404 file not found page, yet all return a 200 ok header status. This means that these, and likely any malformed URLs or URLs that no longer exist, will continue to live on and bloat the index rather than drop out. It also means that the site isn’t sending the highest quality signal to search engines by appearing to return ok statuses for URLs that don’t exist. However, we can also see by the following example that some URLs are returning a proper 404 header status:
- http://www.coldwatercreek.com/GiftCard/%2fGiftCard%2fEGiftCardATB.aspx%3fproductid%3d01GC006%26ensembleid%3d10756
Along with additional examples of possible encoding issues, this is a good reminder that we need to check for issues in different areas of the site and in different ways. This is especially true with complex sites that might appear seamless visually, but may be powered by a number of different scripts, such as a content management system, ecommerce cart, blog, forum and FAQ … all of which might be powered separately.
While we are on that note, my guess is that the following URL probably isn’t of much value either:
- http://www.coldwatercreek.com/Blank.htm
Other examples of possible duplication or diluted content may be seen in the following:
- http://www.coldwatercreek.com/default.aspx (because I still haven’t viewed the site, I don’t know for certain, but experience and my gut tells me that this may be a duplication of the homepage URL, http://www.coldwatercreek.com/).
Another challenging area for duplication is in presentation, and my guess is that:
- http://www.coldwatercreek.com/apparel/pants/longs.aspx
is probably being duplicated by:
- http://www.coldwatercreek.com/apparel/pants/longs.aspx?ShowAllProducts=false
Which is prevalent for all products that have pagination, and to some extent, duplicated further by the counter URL variation:
- http://www.coldwatercreek.com/apparel/pants/longs.aspx?ShowAllProducts=true
At this point, we don’t know if these are being dealt with in other ways, such as robots handling, nofollow link attributes or the canonical link element. Nor can we determine how these should be handled, but at least we have a better understanding of what is going on and what we need to dig into.
Related to that, we also have a quick view into the pagination URL construct:
- http://www.coldwatercreek.com/apparel/pants/longs.aspx?page=1
- http://www.coldwatercreek.com/apparel/pants/longs.aspx?page=2
In addition, some other URLs that are probably low value for search (as well as possible encoding issues again) that we’ll want to check to see whether they are being excluded from the bots:
- http://www.coldwatercreek.com/GiftCard/%2fGiftCard%2fGiftCardATB.aspx%3fproductid%3d44130%26ensembleid%3d50183
- http://www.coldwatercreek.com/GiftCard/EGiftCard.aspx?productid=01GC001&ensembleid=10756
While we are looking at URLs, we can quickly scan our Excel file and identify key URL constructs being used.
Such as parameter-based product detail pages, including perhaps low-value duplication:
- http://www.coldwatercreek.com/Products/Detail.aspx?productid=30144&ensembleid=34281
- http://www.coldwatercreek.com/Products/Detail.aspx?productid=30144&ensembleid=34281&Skn=outlet
Some lengthy, a little parameter heavy and generally ugly URLs that may be challenging to bots:
- http://www.coldwatercreek.com/Products/prodList.aspx?provider=productsearch&cmd=czcategory&cat=All+Products////Apparel////Dresses////UserSearch=Dept.Channel+ID=1&ShowAllProducts=false
- http://www.coldwatercreek.com/Sale/default.aspx?provider=productsearch&cmd=czNewPage&path=All+Products////UserSearch=RedTag////UserSearch=Misses&page=18
Especially in comparison to the cleaner, keyword friendly category pages (though I’d still want to review these around the pagination construct mentioned earlier):
- http://www.coldwatercreek.com/knit-dresses.aspx
- http://www.coldwatercreek.com/misses.aspx
- http://www.coldwatercreek.com/outlet-jackets.aspx
Seem like a lot of focus on URLs? You bet. URLs are at the foundation of a site’s SEO. Get these wrong and little else matters. Xenu is excellent at seeing the URLs that exist that may not ever make it into a search engine index … which may be quite telling. So remember that a “site:domain.com” advanced query only reveals what is “above water.”
The Cold Water Creek site is actually quite small with only a few variations of URLs. The real power and beauty of Xenu is when you find yourself reviewing 300,000+ URLs from highly complex sites with several URL constructs and variants.
In part 2 of the Blindfolded SEO Audit, we’ll start out by seeing what Xenu can show us about the most important search signal a site has.
Possible Related Posts
Posted by Brian R. Brown of Netconcepts on 10/21/2009
Permalink | |  Print
| Trackback | Comments (0) | Comments RSS
Print
| Trackback | Comments (0) | Comments RSS
Filed under: General, SEO, Tools, Tricks, URLs duplication, seo audit, Tools, URLs, xenu


No comments for Blindfolded SEO Audit Part 1
No comments yet.
Sorry, the comment form is closed at this time.