Dr. Paul W.K. Rothemund and Dr. Eric Winfree awarded the Feynman Prize at nanoTX Conference
Dr. Paul W.K. Rothemund and Dr. Eric Winfree were awarded the 2006 Foresight Institute Feynman Prizes at the nanoTX Conference last week, at a special awards reception. (I earlier blogged about H. Ross Perot’s keynote address at this conference.)
Rothemund was on-hand to receive the award, and I was fortunate to be able to attend his presentation on his and Winfree’s research. Rothemund delivered first a presentation on his work, and then he delivered a presentation on behalf of Winfree who could not attend.
Rothemund’s work is fantastic — he works upon Algorithmic Self-Assembly. He’s been able to program long strands of viral DNA such than when mixed in a suspension with other short DNA snippets (and heated slightly), the snippets or “staples” will bind to the long strand in particular order, causing it to fold back upon itself to form precise shapes. Rothemund has nicknamed what he does as “DNA Origami”, although the key concept is the ability to program the DNA to order itself into near two-dimensional, or even three-dimensional shapes. As proof of concept, Rothemund has programmed DNA to fold itself into words, stars, smiley faces, and other shapes.

Smiley composed of one long DNA strand
The staple snippets of DNA are not shown in this representation.
(Illustration copyright 2006 by Chris Silver Smith.)
Possible Related Posts
Posted by Chris of Silvery on 10/02/2006
Permalink | |  Print
| Trackback | Comments Off on Dr. Paul W.K. Rothemund and Dr. Eric Winfree awarded the Feynman Prize at nanoTX Conference | Comments RSS
Print
| Trackback | Comments Off on Dr. Paul W.K. Rothemund and Dr. Eric Winfree awarded the Feynman Prize at nanoTX Conference | Comments RSS
Filed under: Futurism, General, technology Algorithms, artificial-intelligence, DNA, future, Futurism, nano, nanotech
Yahoo update beefs up on authority sites
Aaron Wall posted a blog about how Yahoo!’s recent algorithm update has apparently increased weighting factors for links and authority sites.
Predictibly, a number of folx have complained in the comments added to Yahoo’s “Weather Report” blog about the update. Jeremy Zawodny subsequently posted that their search team was paying close attention to the comments, which is always nice to hear.
Coincidentally, I’d also just recently posted about Google’s apparent use of page text to help identify a site’s overall authoritativeness for particular keywords/themes.
As they say, there’s nothing really new under the sun. I wonder if the search engines are all returning to the trend of authority/hub focus in algorithm development? It’s a strong concept and useful for ranking results, so the methodology for identifying authorities and hubs is likely here to stay.
Possible Related Posts
Posted by Chris of Silvery on 07/20/2006
Permalink | | Print
| Trackback | Comments Off on Yahoo update beefs up on authority sites | Comments RSS
Filed under: General, Yahoo Algorithms, Authoritative-Hubs, authorities, Google, search-engine-algorithms, search-engines, SEO, Yahoo
Google Sitemaps Reveal Some of the Black Box
I earlier mentioned the recent Sitemaps upgrades which were announced in June, and how I thought these were useful for webmasters. But, the Sitemaps tools may also be useful in other ways beyond the obvious/intended ones.
The information that Google has made available in Sitemaps is providing a cool bit of intel on yet another one of the 200+ parameters or “signals” that they’re using to rank pages for SERPs.
For reference, check out the Page Analysis Statistics that are provided in Sitemaps for my “Acme” products and services experimental site:
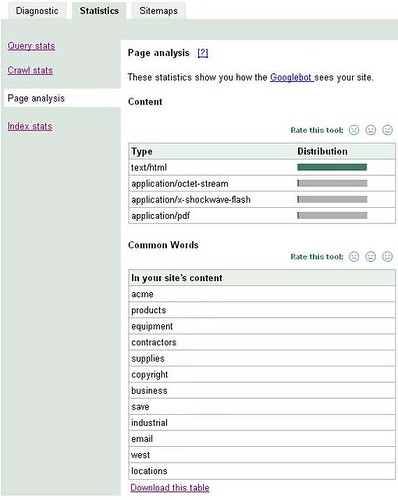
It seems unlikely to me that these stats on “Common Words” found “In your site’s content” were generated just for the sake of providing nice tools for us in Sitemaps. No, the more likely scenario would seem to be that Google was already collating the most-common words found on your site for their own uses, and then they later chose to provide some of these stats to us in Sitemaps.
This is significant, because we’ve already known that Google tracks keyword content for each page in order to assess its relevancy for search queries made with that term. But, why would Google be tracking your most-common keywords in a site-wide context?
One good explanation presents itself: Google might be tracking common terms used throughout a site in order to assess if that site should be considered authoritative for particular keywords or thematic categories.
Early on, algorithmic researchers such as Jon Kleinberg worked on methods by which “authoritative” sites and “hubs” could be identified. IBM and others did further research on authority/hub identification, and I heard engineers from Teoma speak on the importance of these approaches a few times at SES conferences when explaining the ExpertRank system their algorithms were based upon.
So, it’s not all that surprising that Google may be trying to use commonly-occuring text to help identify Authoritative sites for various themes. This would be one good automated method for classifying sites for subject matter categories and keywords.
The take-away concept is that Google may be using words found in the visible text throughout your site to assess whether you’re authoritative for particular themes or not.
Â
Possible Related Posts
Posted by Chris of Silvery on 07/11/2006
Permalink | | Print
| Trackback | Comments Off on Google Sitemaps Reveal Some of the Black Box | Comments RSS
Filed under: Google, Tools Algorithms, Authoritative-Hubs, ExpertRank, Google, Hubs, Keyword-Classification, On-Page-Factors, PageRank, Search Engine Optimization, SEO, Sitemaps

