Relationship Between Link Growth And Indexation
With every passing day, the number of websites and hence the number of web pages are growing at an explosive rate on the internet. This can cause a major headache to the search engines as they gear up to meet the challenge of crawling and subsequently indexing the new sites popping up everywhere in the cybersphere.
Today, when a new web site is launched, it will take a while before its pages get crawled and indexed in Google. With the increasing strain on hardware and resources due to the rapid growth of new sites, Google has become very strict in its policy of admitting sites and retaining web pages of sites in its index. It is a case of survival of the fittest in cyberspace.
Possible Related Posts
Posted by Ravi of Netconcepts Ltd. on 11/29/2009
Permalink | |  Print
| Trackback | Comments (0) | Comments RSS
Print
| Trackback | Comments (0) | Comments RSS
Filed under: Link Building, PageRank, Search Engine Optimization, SEO Add new tag, auckland seo firm, baclinks, crawling, directory submission, editorial links, external linking profile, google index, indexation, link growth, link growth patterns, linkbait, linkerati, natural link building, Netconcepts, PageRank, ppc services, search engine optimisation, value of deep links, virtual real estate
Key Factors To Include In Competitive Analysis
As a site owner, you would be analyzing the Google SERPs (Search Engine Result Pages) frequently to see the sites ranking on Page 1 for terms that are of particular interest to your business or niche. Today it is vital to rank in the top 5 results on the first page to get the lion’s share of user clicks (approximately 70%).
Ranking below the fold on page 1 or on succeeding pages is not going to help your site’s cause in gaining better visibility and hence more traffic. The key factors you have to consider when doing a competitive analysis to dethrone a site ranking in the top 5 results and get your site listed in its place is what constitutes the meat of this post.
Possible Related Posts
Posted by Ravi of Netconcepts Ltd. on 10/11/2009
Permalink | | Print
| Trackback | Comments (0) | Comments RSS
Filed under: Search Engine Optimization, SEO anchor text of inbound links, auckland search engine optimisation, competitive analysis factors, domain diversity, domain metrics, domain mozRank, domain size, domain trust, external links, keyword targeting, linking domains, mR or mozRank, mT or mozTrust, page metrics, PageRank, SEO
Link Building Tactics That Influence Search Engine Ranking Factors
Today’s post dwells on the discussion of link buillding tactics that influence search engine ranking factors in 2009. Link acquisition is a key component of the ranking algorithms. The number of external links pointing to your site and the anchor text contained therein can certainly propel your site to the top of the search results pages.
I will be discussing only the top 4 factors under each section with a mention of the value score allotted by the SEO professionals . This biennial survey by Rand Fishkin at SEOMoz picks the brains of the top 72 SEO professionals from all over the world and their collective wisdom is presented in this post.
Possible Related Posts
Posted by Ravi of Netconcepts Ltd. on 09/13/2009
Permalink | | Print
| Trackback | Comments (0) | Comments RSS
Filed under: Best Practices, Link Building, PageRank, Searching, SEO blogging, blogosphere, content creation, domain trust, editorial content, editorial link, effectiveness of link building tactics using seo, global authority of domain, keyword anchor text of link, link building tactics for seo, link-bait, PageRank, pagerank passed by a link, press release, public relations, TrustRank, value of external links, viral content creation
Search Engine Crawling and Indexing Factors
The post today is about getting a site crawled and indexed effectively by the major search engines. It can be frustrating for a site owner to find that her newly built site with bells and whistles is just not appearing on the Google SERPs for a search query relevant to her business.
It is a good idea to have some knowledge of the factors that influence the crawling of a site and its successful indexing before the site ranks on the SERPs. The site can be built in a user friendly way that allows the spiders to know what to crawl and how frequently to crawl.
(more…)
Possible Related Posts
Posted by Ravi of Netconcepts Ltd. on 07/05/2009
Permalink | | Print
| Trackback | Comments (0) | Comments RSS
Filed under: Search Engine Optimization, SEO, Spiders backlinks, content freshness, crawling factors, domain importance, duplicate-content, external links, Feeds, google-webmaster-tools, increase crawl rate, Links, PageRank, query deserves freshness, search engine crawling, search engine indexing, signals, supplemental index, technical factors, unique content
Google Takes RSS & Atom Feeds out of Web Search Results
Google just announced this week that they have started reducing RSS & Atom feeds out of their search engine results pages (“SERPs”) – something that makes a lot of sense in terms of improving quality/usability in their results. (They also describe why they aren’t doing that for podcast feeds.)
This might confuse search marketers about the value of providing RSS feeds on one’s site for the purposes of natural search marketing. Here at Netconcepts, we’ve recommended using RSS for retail sites and blogs for quite some time, and we continue to do so. Webmasters often take syndicated feeds in order to provide helpful content and utilities on their sites, and so providing feeds can help you to gain external links pointing back to your site when webmasters display your feed content on their pages.
Google has removed RSS feed content from their regular SERPs, but they haven’t necessarily reduced any of the benefit of the links produced when those feeds are adopted and displayed on other sites. When RSS and Atom feeds are used by developers, they pull in the feed content and then typically redisplay it on their site pages in regular HTML formatting. When those pages link back to you as many feed-displayed pages do, the links transfer PageRank back to the site originating the feeds, and this results in building up ranking values.
So, don’t stop using RSS or Atom feeds!
Possible Related Posts
Posted by Chris of Silvery on 12/19/2007
Permalink | | Print
| Trackback | Comments Off on Google Takes RSS & Atom Feeds out of Web Search Results | Comments RSS
Filed under: Blog Optimization, Google, URLs ATOM, Feeds, Google, PageRank, RSS
Google Employees Can’t Find PageRank – Must Search For It
Last night, I was comparing relative popularity of a few keywords in Google Trends, and I noticed that the term, “PageRank”, apparently has the highest number of searches in the US from people in the city of Mountain View, California:
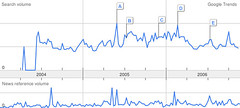

http://www.google.com/trends?q=pagerank&ctab=0&geo=US&date=all
As you may be aware, Google headquarters is located in Mountain View (see map).
So the most likely reason that most USÂ “PageRank” searches happen in that little town is that Google employees are frequently submitting searches for info about PageRank. They may be searching for what people are saying about PageRank, or they may be searching for new research papers concerning the algorithm. But, they’re definitely searching for it…
For the one place in the world that has the most PageRank of all, you’d think they wouldn’t have to search for it. 😉
Â
Â
Possible Related Posts
Posted by Chris of Silvery on 02/23/2007
Permalink | | Print
| Trackback | Comments Off on Google Employees Can’t Find PageRank – Must Search For It | Comments RSS
Filed under: Google, PageRank Google, Google-Trends, PageRank
Leveraging Wikipedia for SEO: it’s no longer about the link juice
Recently when I blogged about the SEO benefits of contributing to Wikipedia, I alluded to some of the complex strategies and tactics around creating entries, keeping your edits from getting reverted, etc.
One of the benefits that can no longer be gained is link juice. That’s because rel=nofollow has just been instituted across all of Wikipedia and its sister sites (such as Wikinews).
Does that mean you no longer need to concern yourself with Wikipedia? Heck no! It is still a valuable source of traffic and, just as importantly, credibility. To have a Wikipedia entry for your company show up in the top 10 in Google for your company name gives a nice credibility boost. Even better if the coverage on your entry is favorable!
Wikipedia is still key to the discipline of “reputation management.” By understanding the ins and outs of Wikipedia — navigating the landmines of notability criteria, not contributing your company’s entry yourself, disambiguation pages, redirects, User pages, Talk pages, etc. — you can potentially influence what is said about you on Wikipedia. Furthermore, if web pages that are critical of your company occupy spots in the first page of the SERPs, you can push them out and replace them with your Wikipedia entries. Because Wikipedia holds so much authority and TrustRank, it’s easy to get an entry into the top 10 for any keyword.
Back to the nofollowing of external links… I don’t think SEOs will leave Wikipedia any time soon due to this new development. Even though that was Jimbo Wales’ hope.
There is still significant incentive for SEOs to edit (and manipulate) Wikipedia so long as Wikipedia holds the top spot for important keywords such as “marketing” in Google.
Possible Related Posts
Posted by stephan of stephan on 01/23/2007
Permalink | | Print
| Trackback | Comments Off on Leveraging Wikipedia for SEO: it’s no longer about the link juice | Comments RSS
Filed under: Link Building, PageRank Link Building, link-gain, PageRank, reputation-management, TrustRank, Wikipedia
Hey Digg! Fix your domain name for better SEO traffic!
Hey, Digg.com team! Are you aware that your domain names aren’t properly canonized? You may be losing out on good ranking value in Google and Yahoo because of this!
Even if you’re not part of the Digg technical team, this same sort of scenario could be affecting your site’s rankings. This aspect of SEO is pretty simple to address, so don’t ignore it and miss out on PageRank that should be yours. Read on for a simple explanation.
Possible Related Posts
Posted by Chris of Silvery on 10/04/2006
Permalink | | Print
| Trackback | Comments Off on Hey Digg! Fix your domain name for better SEO traffic! | Comments RSS
Filed under: Search Engine Optimization, SEO, Social Media Optimization, URLs digg, Google, PageRank, SEO, url-canonization, Yahoo
Using Flickr for Search Engine Optimization
I’ve previously blogged about optimization for Image Search. But, images can also be used for optimization for regular web search as well. Where online promotion is concerned, it appears to be an area for advantage which remains largely untapped. Many pros focus most of their optimization efforts towards the more popular web search results, and don’t realize that optimizing for image search can translate to good overall SEO.
Flickr is one of the most popular image sharing sites in the world, with loads of features that also make it qualify as a social networking site. Flickr’s popularity, structure and features also make it an ideal vehicle for search engine optimization. So, how can image search optimization be done through Flickr? Read on, and I’ll outline some key steps to take. (more…)
Possible Related Posts
Posted by Chris of Silvery on 09/24/2006
Permalink | | Print
| Trackback | Comments Off on Using Flickr for Search Engine Optimization | Comments RSS
Filed under: Image Optimization, Search Engine Optimization, SEO flickr, Image-Search-Optimization, PageRank, Search Engine Optimization, SEO
A window into Google through error messages: PageRank vectors and IndyRank
There’s been plenty of speculation posted to the blogosphere on the recently discovered cryptic Google error message; my favorites being from Wesley Tanaka and from Teh Xiggeh.
What intrigues me most in the Google error message is the references to IndyRank and to PageRank possibly being a vector. In regards to IndyRank, Stuart Brown suspects it means an ‘independent ranking’ — a “human-derived page ranking scoring, independent of the concrete world of linking and keywords”.
In regards to a PageRank vector, Wesley hypothesizes:
“If page rank is actually a vector (multiple numbers) as opposed to a scalar (single number) like everyone assumes (and like is displayed by the toolbar). It would make sense — the page rank for a page could store other aspects of the page, like how likely it is to be spam, in addition to an idea of how linked-to the page is. The page rank you see in the google toolbar would be some scalar function of the page rank vector.”
Of course the Google engineers are probably laughing at all this.
Possible Related Posts
Posted by stephan of stephan on 07/22/2006
Permalink | | Print
| Trackback | Comments Off on A window into Google through error messages: PageRank vectors and IndyRank | Comments RSS
Filed under: Google, PageRank Google, IndyRank, PageRank, vectors

